这篇文章主要介绍“Java缓存技术怎么使用”,在日常操作中,相信很多人在Java缓存技术怎么使用问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Java缓存技术怎么使用”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!

为什么我们需要缓存?
很久很久以前,在还没有缓存的时候……用户经常是去请求一个对象,而这个对象是从数据库去取,然后,这个对象变得越来越大,这个用户每次的请求时间也越来越长了,这也把数据库弄得很痛苦,他无时不刻不在工作。所以,这个事情就把用户和数据库弄得很生气,接着就有可能发生下面两件事情:
1.用户很烦,在抱怨,甚至不去用这个应用了(这是大多数情况下都会发生的)
2.数据库为打包回家,离开这个应用,然后,就出现了麻烦(没地方去存储数据了)(发生在极少数情况下)
上帝派来了缓存
在几年之后,IBM(60年代)的研究人员引进了一个新概念,它叫“缓存”。
什么是缓存?
正如开篇所讲,缓存是“存贮数据(使用频繁的数据)的临时地方,因为取原始数据的代价太大了,所以我可以取得快一些。”
缓存可以认为是数据的池,这些数据是从数据库里的真实数据复制出来的,并且为了能正确取回,被标上了标签(键 ID)。太棒了
programmer one 已经知道这点了,但是他还不知道下面的缓存术语。
命中:
当客户发起一个请求(我们说他想要查看一个产品信息),我们的应用接受这个请求,并且如果是在第一次检查缓存的时候,需要去数据库读取产品信息。
如果在缓存中,一个条目通过一个标记被找到了,这个条目就会被使用、我们就叫它缓存命中。所以,命中率也就不难理解了。
Cache Miss:
但是这里需要注意两点:
1. 如果还有缓存的空间,那么,没有命中的对象会被存储到缓存中来。
2. 如果缓存满了,而又没有命中缓存,那么就会按照某一种策略,把缓存中的旧对象踢出,而把新的对象加入缓存池。而这些策略统称为替代策略(缓存算法),这些策略会决定到底应该提出哪些对象。
存储成本:
当没有命中时,我们会从数据库取出数据,然后放入缓存。而把这个数据放入缓存所需要的时间和空间,就是存储成本。
索引成本:
和存储成本相仿。
失效:
当存在缓存中的数据需要更新时,就意味着缓存中的这个数据失效了。
替代策略:
当缓存没有命中时,并且缓存容量已经满了,就需要在缓存中踢出一个老的条目,加入一条新的条目,而到底应该踢出什么条目,就由替代策略决定。
最优替代策略:
最优的替代策略就是想把缓存中最没用的条目给踢出去,但是未来是不能够被预知的,所以这种策略是不可能实现的。但是有很多策略,都是朝着这个目前去努力。
缓存算法
没有人能说清哪种缓存算法优于其他的缓存算法
Least Frequently Used(LFU):
大家好,我是 LFU,我会计算为每个缓存对象计算他们被使用的频率。我会把最不常用的缓存对象踢走。
Least Recently User(LRU):
我是 LRU 缓存算法,我把最近最少使用的缓存对象给踢走。
我总是需要去了解在什么时候,用了哪个缓存对象。如果有人想要了解我为什么总能把最近最少使用的对象踢掉,是非常困难的。
浏览器就是使用了我(LRU)作为缓存算法。新的对象会被放在缓存的顶部,当缓存达到了容量极限,我会把底部的对象踢走,而技巧就是:我会把最新被访问的缓存对象,放到缓存池的顶部。
所以,经常被读取的缓存对象就会一直呆在缓存池中。有两种方法可以实现我,array 或者是 linked list。
我的速度很快,我也可以被数据访问模式适配。我有一个大家庭,他们都可以完善我,甚至做的比我更好(我确实有时会嫉妒,但是没关系)。我家庭的一些成员包括 LRU2 和 2Q,他们就是为了完善 LRU 而存在的。
First in First out(FIFO):
我是先进先出,我是一个低负载的算法,并且对缓存对象的管理要求不高。我通过一个队列去跟踪所有的缓存对象,最近最常用的缓存对象放在后面,而更早的缓存对象放在前面,当缓存容量满时,排在前面的缓存对象会被踢走,然后把新的缓存对象加进去。我很快,但是我并不适用。
Second Chance:
大家好,我是 second chance,我是通过 FIFO 修改而来的,被大家叫做 second chance 缓存算法,我比 FIFO 好的地方是我改善了 FIFO 的成本。我是 FIFO 一样也是在观察队列的前端,但是很FIFO的立刻踢出不同,我会检查即将要被踢出的对象有没有之前被使用过的标志(1一个 bit 表示),没有被使用过,我就把他踢出;否则,我会把这个标志位清除,然后把这个缓存对象当做新增缓存对象加入队列。你可以想象就这就像一个环队列。当我再一次在队头碰到这个对象时,由于他已经没有这个标志位了,所以我立刻就把他踢开了。我在速度上比 FIFO 快。
其他的缓存算法还考虑到了下面几点:
成本:如果缓存对象有不同的成本,应该把那些难以获得的对象保存下来。
容量:如果缓存对象有不同的大小,应该把那些大的缓存对象清除,这样就可以让更多的小缓存对象进来了。
时间:一些缓存还保存着缓存的过期时间。电脑会失效他们,因为他们已经过期了。
根据缓存对象的大小而不管其他的缓存算法可能是有必要的。
看看缓存元素(缓存实体)
public class CacheElement
{
private Object objectValue;
private Object objectKey;
private int index;
private int hitCount; // getters and setters
}这个缓存实体拥有缓存的key和value,这个实体的数据结构会被以下所有缓存算法用到。
缓存算法的公用代码
public final synchronized void addElement(Object key, Object value)
{
int index;
Object obj;
// get the entry from the table
obj = table.get(key);
// If we have the entry already in our table
// then get it and replace only its value.
obj = table.get(key);
if (obj != null)
{
CacheElement element;
element = (CacheElement) obj;
element.setObjectValue(value);
element.setObjectKey(key);
return;
}
}上面的代码会被所有的缓存算法实现用到。这段代码是用来检查缓存元素是否在缓存中了,如果是,我们就替换它,但是如果我们找不到这个 key 对应的缓存,我们会怎么做呢?那我们就来深入的看看会发生什么吧!
现场访问
今天的专题很特殊,因为我们有特殊的客人,事实上他们是我们想要听的与会者,但是首先,先介绍一下我们的客人:Random Cache,FIFO Cache。让我们从 Random Cache开始。
看看随机缓存的实现
public final synchronized void addElement(Object key, Object value)
{
int index;
Object obj;
obj = table.get(key);
if (obj != null)
{
CacheElement element;// Just replace the value.
element = (CacheElement) obj;
element.setObjectValue(value);
element.setObjectKey(key);
return;
}// If we haven't filled the cache yet, put it at the end.
if (!isFull())
{
index = numEntries;
++numEntries;
}
else { // Otherwise, replace a random entry.
index = (int) (cache.length * random.nextFloat());
table.remove(cache[index].getObjectKey());
}
cache[index].setObjectValue(value);
cache[index].setObjectKey(key);
table.put(key, cache[index]);
}看看FIFO缓算法的实现
public final synchronized void addElement(Objectkey, Object value)
{
int index;
Object obj;
obj = table.get(key);
if (obj != null)
{
CacheElement element; // Just replace the value.
element = (CacheElement) obj;
element.setObjectValue(value);
element.setObjectKey(key);
return;
}
// If we haven't filled the cache yet, put it at the end.
if (!isFull())
{
index = numEntries;
++numEntries;
}
else { // Otherwise, replace the current pointer,
// entry with the new one.
index = current;
// in order to make Circular FIFO
if (++current >= cache.length)
current = 0;
table.remove(cache[index].getObjectKey());
}
cache[index].setObjectValue(value);
cache[index].setObjectKey(key);
table.put(key, cache[index]);
}看看LFU缓存算法的实现
public synchronized Object getElement(Object key)
{
Object obj;
obj = table.get(key);
if (obj != null)
{
CacheElement element = (CacheElement) obj;
element.setHitCount(element.getHitCount() + 1);
return element.getObjectValue();
}
return null;
}
public final synchronized void addElement(Object key, Object value)
{
Object obj;
obj = table.get(key);
if (obj != null)
{
CacheElement element; // Just replace the value.
element = (CacheElement) obj;
element.setObjectValue(value);
element.setObjectKey(key);
return;
}
if (!isFull())
{
index = numEntries;
++numEntries;
}
else
{
CacheElement element = removeLfuElement();
index = element.getIndex();
table.remove(element.getObjectKey());
}
cache[index].setObjectValue(value);
cache[index].setObjectKey(key);
cache[index].setIndex(index);
table.put(key, cache[index]);
}
public CacheElement removeLfuElement()
{
CacheElement[] elements = getElementsFromTable();
CacheElement leastElement = leastHit(elements);
return leastElement;
}
public static CacheElement leastHit(CacheElement[] elements)
{
CacheElement lowestElement = null;
for (int i = 0; i < elements.length; i++)
{
CacheElement element = elements[i];
if (lowestElement == null)
{
lowestElement = element;
}
else {
if (element.getHitCount() < lowestElement.getHitCount())
{
lowestElement = element;
}
}
}
return lowestElement;
}最重点的代码,就应该是 leastHit 这个方法,这段代码就是把hitCount 最低的元素找出来,然后删除,给新进的缓存元素留位置
看看LRU缓存算法实现
private void moveToFront(int index)
{
int nextIndex, prevIndex;
if(head != index)
{
nextIndex = next[index];
prevIndex = prev[index];
// Only the head has a prev entry that is an invalid index
// so we don't check.
next[prevIndex] = nextIndex;
// Make sure index is valid. If it isn't, we're at the tail
// and don't set prev[next].
if(nextIndex >= 0)
prev[nextIndex] = prevIndex;
else
tail = prevIndex;
prev[index] = -1;
next[index] = head;
prev[head] = index;
head = index;
}
}
public final synchronized void addElement(Object key, Object value)
{
int index;Object obj;
obj = table.get(key);
if(obj != null)
{
CacheElement entry;
// Just replace the value, but move it to the front.
entry = (CacheElement)obj;
entry.setObjectValue(value);
entry.setObjectKey(key);
moveToFront(entry.getIndex());
return;
}
// If we haven't filled the cache yet, place in next available
// spot and move to front.
if(!isFull())
{
if(_numEntries > 0)
{
prev[_numEntries] = tail;
next[_numEntries] = -1;
moveToFront(numEntries);
}
++numEntries;
}
else { // We replace the tail of the list.
table.remove(cache[tail].getObjectKey());
moveToFront(tail);
}
cache[head].setObjectValue(value);
cache[head].setObjectKey(key);
table.put(key, cache[head]);
}这段代码的逻辑如 LRU算法 的描述一样,把再次用到的缓存提取到最前面,而每次删除的都是最后面的元素。
一般而言,现在互联网应用(网站或App)的整体流程,可以概括如图1所示,用户请求从界面(浏览器或App界面)到网络转发、应用服务再到存储(数据库或文件系统),然后返回到界面呈现内容。
随着互联网的普及,内容信息越来越复杂,用户数和访问量越来越大,我们的应用需要支撑更多的并发量,同时我们的应用服务器和数据库服务器所做的计算也越来越多。但是往往我们的应用服务器资源是有限的,且技术变革是缓慢的,数据库每秒能接受的请求次数也是有限的(或者文件的读写也是有限的),如何能够有效利用有限的资源来提供尽可能大的吞吐量?一个有效的办法就是引入缓存,打破标准流程,每个环节中请求可以从缓存中直接获取目标数据并返回,从而减少计算量,有效提升响应速度,让有限的资源服务更多的用户。
缓存也是一个数据模型对象,那么必然有它的一些特征:
命中率=返回正确结果数/请求缓存次数,命中率问题是缓存中的一个非常重要的问题,它是衡量缓存有效性的重要指标。命中率越高,表明缓存的使用率越高。
缓存中可以存放的大元素的数量,一旦缓存中元素数量超过这个值(或者缓存数据所占空间超过其大支持空间),那么将会触发缓存启动清空策略根据不同的场景合理的设置大元素值往往可以一定程度上提高缓存的命中率,从而更有效的时候缓存。
如上描述,缓存的存储空间有限制,当缓存空间被用满时,如何保证在稳定服务的同时有效提升命中率?这就由缓存清空策略来处理,设计适合自身数据特征的清空策略能有效提升命中率。常见的一般策略有:
FIFO(first in first out)
先进先出策略,最先进入缓存的数据在缓存空间不够的情况下(超出大元素限制)会被优先被清除掉,以腾出新的空间接受新的数据。策略算法主要比较缓存元素的创建时间。在数据实效性要求场景下可选择该类策略,优先保障最新数据可用。
LFU(less frequently used)
最少使用策略,无论是否过期,根据元素的被使用次数判断,清除使用次数较少的元素释放空间。策略算法主要比较元素的hitCount(命中次数)。在保证高频数据有效性场景下,可选择这类策略。
LRU(least recently used)
最近最少使用策略,无论是否过期,根据元素最后一次被使用的时间戳,清除最远使用时间戳的元素释放空间。策略算法主要比较元素最近一次被get使用时间。在热点数据场景下较适用,优先保证热点数据的有效性。
除此之外,还有一些简单策略比如:
根据过期时间判断,清理过期时间最长的元素;
根据过期时间判断,清理最近要过期的元素;
随机清理;
根据关键字(或元素内容)长短清理等。
虽然从硬件介质上来看,无非就是内存和硬盘两种,但从技术上,可以分成内存、硬盘文件、数据库。
内存:将缓存存储于内存中是最快的选择,无需额外的I/O开销,但是内存的缺点是没有持久化落地物理磁盘,一旦应用异常break down而重新启动,数据很难或者无法复原。
硬盘:一般来说,很多缓存框架会结合使用内存和硬盘,在内存分配空间满了或是在异常的情况下,可以被动或主动的将内存空间数据持久化到硬盘中,达到释放空间或备份数据的目的。
数据库:前面有提到,增加缓存的策略的目的之一就是为了减少数据库的I/O压力。现在使用数据库做缓存介质是不是又回到了老问题上了?其实,数据库也有很多种类型,像那些不支持SQL,只是简单的key-value存储结构的特殊数据库(如BerkeleyDB和Redis),响应速度和吞吐量都远远高于我们常用的关系型数据库等。
缓存有各类特征,而且有不同介质的区别,那么实际工程中我们怎么去对缓存分类呢?在目前的应用服务框架中,比较常见的,时根据缓存雨应用的藕合度,分为local cache(本地缓存)和remote cache(分布式缓存):
本地缓存:指的是在应用中的缓存组件,其大的优点是应用和cache是在同一个进程内部,请求缓存非常快速,没有过多的网络开销等,在单应用不需要集群支持或者集群情况下各节点无需互相通知的场景下使用本地缓存较合适;同时,它的缺点也是应为缓存跟应用程序耦合,多个应用程序无法直接的共享缓存,各应用或集群的各节点都需要维护自己的单独缓存,对内存是一种浪费。
分布式缓存:指的是与应用分离的缓存组件或服务,其大的优点是自身就是一个独立的应用,与本地应用隔离,多个应用可直接的共享缓存。
目前各种类型的缓存都活跃在成千上万的应用服务中,还没有一种缓存方案可以解决一切的业务场景或数据类型,我们需要根据自身的特殊场景和背景,选择最适合的缓存方案。缓存的使用是程序员、架构师的必备技能,好的程序员能根据数据类型、业务场景来准确判断使用何种类型的缓存,如何使用这种缓存,以最小的成本最快的效率达到最优的目的。
个别场景下,我们只需要简单的缓存数据的功能,而无需关注更多存取、清空策略等深入的特性时,直接编程实现缓存则是最便捷和高效的。
a. 成员变量或局部变量实现
简单代码示例如下:
public void UseLocalCache(){
//一个本地的缓存变量
Map localCacheStoreMap = new HashMap();
List 以局部变量map结构缓存部分业务数据,减少频繁的重复数据库I/O操作。缺点仅限于类的自身作用域内,类间无法共享缓存。
b. 静态变量实现
最常用的单例实现静态资源缓存,代码示例如下:
public class CityUtils {
private static final HttpClient httpClient = ServerHolder.createClientWithPool();
private static Map cityIdNameMap = new HashMap();
private static Map districtIdNameMap = new HashMap();
static {
HttpGet get = new HttpGet("http://gis-in.sankuai.com/api/location/city/all");
BaseAuthorizationUtils.generateAuthAndDateHeader(get,
BaseAuthorizationUtils.CLIENT_TO_REQUEST_MDC,
BaseAuthorizationUtils.SECRET_TO_REQUEST_MDC);
try {
String resultStr = httpClient.execute(get, new BasicResponseHandler());
JSONObject resultJo = new JSONObject(resultStr);
JSONArray dataJa = resultJo.getJSONArray("data");
for (int i = 0; i < dataJa.length(); i++) {
JSONObject itemJo = dataJa.getJSONObject(i);
cityIdNameMap.put(itemJo.getInt("id"), itemJo.getString("name"));
}
} catch (Exception e) {
throw new RuntimeException("Init City List Error!", e);
}
}
static {
HttpGet get = new HttpGet("http://gis-in.sankuai.com/api/location/district/all");
BaseAuthorizationUtils.generateAuthAndDateHeader(get,
BaseAuthorizationUtils.CLIENT_TO_REQUEST_MDC,
BaseAuthorizationUtils.SECRET_TO_REQUEST_MDC);
try {
String resultStr = httpClient.execute(get, new BasicResponseHandler());
JSONObject resultJo = new JSONObject(resultStr);
JSONArray dataJa = resultJo.getJSONArray("data");
for (int i = 0; i < dataJa.length(); i++) {
JSONObject itemJo = dataJa.getJSONObject(i);
districtIdNameMap.put(itemJo.getInt("id"), itemJo.getString("name"));
}
} catch (Exception e) {
throw new RuntimeException("Init District List Error!", e);
}
}
public static String getCityName(int cityId) {
String name = cityIdNameMap.get(cityId);
if (name == null) {
name = "未知";
}
return name;
}
public static String getDistrictName(int districtId) {
String name = districtIdNameMap.get(districtId);
if (name == null) {
name = "未知";
}
return name;
}
} O2O业务中常用的城市基础基本信息判断,通过静态变量一次获取缓存内存中,减少频繁的I/O读取,静态变量实现类间可共享,进程内可共享,缓存的实时性稍差。
这类缓存实现,优点是能直接在heap区内读写,最快也最方便;缺点同样是受heap区域影响,缓存的数据量非常有限,同时缓存时间受GC影响。主要满足单机场景下的小数据量缓存需求,同时对缓存数据的变更无需太敏感感知,如上一般配置管理、基础静态数据等场景。
Ehcache是现在最流行的纯Java开源缓存框架,配置简单、结构清晰、功能强大,是一个非常轻量级的缓存实现,我们常用的Hibernate里面就集成了相关缓存功能。
主要特性:
快速,针对大型高并发系统场景,Ehcache的多线程机制有相应的优化改善。
简单,很小的jar包,简单配置就可直接使用,单机场景下无需过多的其他服务依赖。
支持多种的缓存策略,灵活。
缓存数据有两级:内存和磁盘,与一般的本地内存缓存相比,有了磁盘的存储空间,将可以支持更大量的数据缓存需求。
具有缓存和缓存管理器的侦听接口,能更简单方便的进行缓存实例的监控管理。
支持多缓存管理器实例,以及一个实例的多个缓存区域。
注意:Ehcache的超时设置主要是针对整个cache实例设置整体的超时策略,而没有较好的处理针对单独的key的个性的超时设置(有策略设置,但是比较复杂,就不描述了),因此,在使用中要注意过期失效的缓存元素无法被GC回收,时间越长缓存越多,内存占用也就越大,内存泄露的概率也越大。
memcached是应用较广的开源分布式缓存产品之一,它本身其实不提供分布式解决方案。在服务端,memcached集群环境实际就是一个个memcached服务器的堆积,环境搭建较为简单;cache的分布式主要是在客户端实现,通过客户端的路由处理来达到分布式解决方案的目的。客户端做路由的原理非常简单,应用服务器在每次存取某key的value时,通过某种算法把key映射到某台memcached服务器nodeA上。
无特殊场景下,key-value能满足需求的前提下,使用memcached分布式集群是较好的选择,搭建与操作使用都比较简单;分布式集群在单点故障时,只影响小部分数据异常,目前还可以通过Magent缓存代理模式,做单点备份,提升高可用;整个缓存都是基于内存的,因此响应时间是很快,不需要额外的序列化、反序列化的程序,但同时由于基于内存,数据没有持久化,集群故障重启数据无法恢复。高版本的memcached已经支持CAS模式的原子操作,可以低成本的解决并发控制问题。
Redis是一个远程内存数据库(非关系型数据库),性能强劲,具有复制特性以及解决问题而生的独一无二的数据模型。它可以存储键值对与5种不同类型的值之间的映射,可以将存储在内存的键值对数据持久化到硬盘,可以使用复制特性来扩展读性能,还可以使用客户端分片来扩展写性能。
个人总结了以下多种Web应用场景,在这些场景下可以充分的利用Redis的特性,大大提高效率。
在主页中显示最新的项目列表:Redis使用的是常驻内存的缓存,速度非常快。LPUSH用来插入一个内容ID,作为关键字存储在列表头部。LTRIM用来限制列表中的项目数最多为5000。如果用户需要的检索的数据量超越这个缓存容量,这时才需要把请求发送到数据库。
删除和过滤:如果一篇文章被删除,可以使用LREM从缓存中彻底清除掉。
排行榜及相关问题:排行榜(leader board)按照得分进行排序。ZADD命令可以直接实现这个功能,而ZREVRANGE命令可以用来按照得分来获取前100名的用户,ZRANK可以用来获取用户排名,非常直接而且操作容易。
按照用户投票和时间排序:排行榜,得分会随着时间变化。LPUSH和LTRIM命令结合运用,把文章添加到一个列表中。一项后台任务用来获取列表,并重新计算列表的排序,ZADD命令用来按照新的顺序填充生成列表。列表可以实现非常快速的检索,即使是负载很重的站点。
过期项目处理:使用Unix时间作为关键字,用来保持列表能够按时间排序。对current_time和time_to_live进行检索,完成查找过期项目的艰巨任务。另一项后台任务使用ZRANGE…WITHSCORES进行查询,删除过期的条目。
计数:进行各种数据统计的用途是非常广泛的,比如想知道什么时候封锁一个IP地址。INCRBY命令让这些变得很容易,通过原子递增保持计数;GETSET用来重置计数器;过期属性用来确认一个关键字什么时候应该删除。
特定时间内的特定项目:这是特定访问者的问题,可以通过给每次页面浏览使用SADD命令来解决。SADD不会将已经存在的成员添加到一个集合。
Pub/Sub:在更新中保持用户对数据的映射是系统中的一个普遍任务。Redis的pub/sub功能使用了SUBSCRIBE、UNSUBSCRIBE和PUBLISH命令,让这个变得更加容易。
队列:在当前的编程中队列随处可见。除了push和pop类型的命令之外,Redis还有阻塞队列的命令,能够让一个程序在执行时被另一个程序添加到队列。
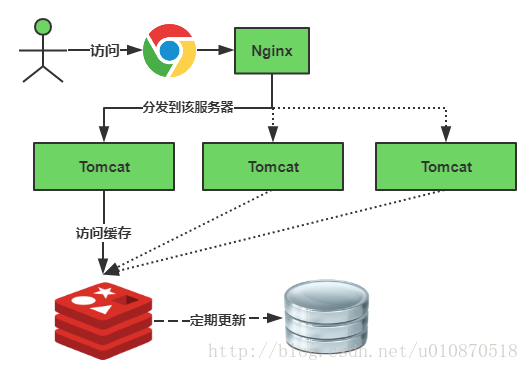
前面一节说到了《 为什么说Redis是单线程的以及Redis为什么这么快!》,今天给大家整理一篇关于Redis经常被问到的问题:缓存雪崩、缓存穿透、缓存预热、缓存更新、缓存降级等概念的入门及简单解决方案。
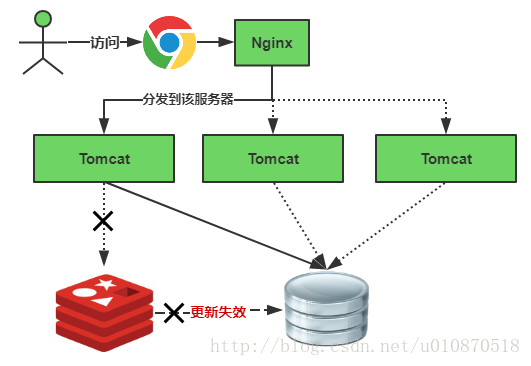
缓存雪崩我们可以简单的理解为:由于原有缓存失效,新缓存未到期间(例如:我们设置缓存时采用了相同的过期时间,在同一时刻出现大面积的缓存过期),所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。
缓存正常从Redis中获取,示意图如下:
缓存失效瞬间示意图如下:
缓存失效时的雪崩效应对底层系统的冲击非常可怕!大多数系统设计者考虑用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。还有一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
以下简单介绍两种实现方式的伪代码:
(1)碰到这种情况,一般并发量不是特别多的时候,使用最多的解决方案是加锁排队,伪代码如下:
//伪代码
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
String lockKey = cacheKey;
String cacheValue = CacheHelper.get(cacheKey);
if (cacheValue != null) {
return cacheValue;
} else {
synchronized(lockKey) {
cacheValue = CacheHelper.get(cacheKey);
if (cacheValue != null) {
return cacheValue;
} else {
//这里一般是sql查询数据
cacheValue = GetProductListFromDB();
CacheHelper.Add(cacheKey, cacheValue, cacheTime);
}
}
return cacheValue;
}
}加锁排队只是为了减轻数据库的压力,并没有提高系统吞吐量。假设在高并发下,缓存重建期间key是锁着的,这是过来1000个请求999个都在阻塞的。同样会导致用户等待超时,这是个治标不治本的方法!
注意:加锁排队的解决方式分布式环境的并发问题,有可能还要解决分布式锁的问题;线程还会被阻塞,用户体验很差!因此,在真正的高并发场景下很少使用!
(2)还有一个解决办法解决方案是:给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存,实例伪代码如下:
//伪代码
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
//缓存标记
String cacheSign = cacheKey + "_sign";
String sign = CacheHelper.Get(cacheSign);
//获取缓存值
String cacheValue = CacheHelper.Get(cacheKey);
if (sign != null) {
return cacheValue; //未过期,直接返回
} else {
CacheHelper.Add(cacheSign, "1", cacheTime);
ThreadPool.QueueUserWorkItem((arg) -> {
//这里一般是 sql查询数据
cacheValue = GetProductListFromDB();
//日期设缓存时间的2倍,用于脏读
CacheHelper.Add(cacheKey, cacheValue, cacheTime * 2);
});
return cacheValue;
}
}解释说明:
1、缓存标记:记录缓存数据是否过期,如果过期会触发通知另外的线程在后台去更新实际key的缓存;
2、缓存数据:它的过期时间比缓存标记的时间延长1倍,例:标记缓存时间30分钟,数据缓存设置为60分钟。 这样,当缓存标记key过期后,实际缓存还能把旧数据返回给调用端,直到另外的线程在后台更新完成后,才会返回新缓存。
关于缓存崩溃的解决方法,这里提出了三种方案:使用锁或队列、设置过期标志更新缓存、为key设置不同的缓存失效时间,还有一各被称为“二级缓存”的解决方法,有兴趣的读者可以自行研究。
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。
有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
另外也有一个更为简单粗暴的方法,如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。通过这个直接设置的默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴!
//伪代码
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
String cacheValue = CacheHelper.Get(cacheKey);
if (cacheValue != null) {
return cacheValue;
}
cacheValue = CacheHelper.Get(cacheKey);
if (cacheValue != null) {
return cacheValue;
} else {
//数据库查询不到,为空
cacheValue = GetProductListFromDB();
if (cacheValue == null) {
//如果发现为空,设置个默认值,也缓存起来
cacheValue = string.Empty;
}
CacheHelper.Add(cacheKey, cacheValue, cacheTime);
return cacheValue;
}
}把空结果,也给缓存起来,这样下次同样的请求就可以直接返回空了,即可以避免当查询的值为空时引起的缓存穿透。同时也可以单独设置个缓存区域存储空值,对要查询的key进行预先校验,然后再放行给后面的正常缓存处理逻辑。
缓存预热这个应该是一个比较常见的概念,相信很多小伙伴都应该可以很容易的理解,缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
解决思路:
1、直接写个缓存刷新页面,上线时手工操作下;
2、数据量不大,可以在项目启动的时候自动进行加载;
3、定时刷新缓存;
除了缓存服务器自带的缓存失效策略之外(Redis默认的有6中策略可供选择),我们还可以根据具体的业务需求进行自定义的缓存淘汰,常见的策略有两种:
(1)定时去清理过期的缓存;
(2)当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。
两者各有优劣,第一种的缺点是维护大量缓存的key是比较麻烦的,第二种的缺点就是每次用户请求过来都要判断缓存失效,逻辑相对比较复杂!具体用哪种方案,大家可以根据自己的应用场景来权衡。
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。
降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)。
在进行降级之前要对系统进行梳理,看看系统是不是可以丢卒保帅;从而梳理出哪些必须誓死保护,哪些可降级;比如可以参考日志级别设置预案:
(1)一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
(2)警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;
(3)错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的大阀值,此时可以根据情况自动降级或者人工降级;
(4)严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
到此,关于“Java缓存技术怎么使用”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注创新互联-成都网站建设公司网站,小编会继续努力为大家带来更多实用的文章!